






Kickoff Meeting
Möchten Sie mehr darüber erfahren, wie wir Ihnen helfen können?
SOFTWAREENTWICKLUNG - DIE GANZE GESCHICHTE
Es funktioniert auf jedem Gerät. Wie wir MVPs programmieren und kontinuierlich weiterentwickeln.
Zum Schluss kommt der spaßige Teil. Sobald wir die User Stories und Wireframes, den geschätzten Zeit- und Kostenrahmen, den Technologie-Stack und einen gründlichen Plan haben, können wir sie in die Tat umsetzen. Dies ist die Geschichte, wie MVPs codiert werden und die Best Practices, die es ermöglichen, dass dieser Code auch auf den Geräten aller anderen funktioniert.

Zur leichteren Lesbarkeit haben wir es in vier Stufen unterteilt:
1. Setup
1.1 Entwicklungsumgebung
2. Entwicklung
2.1 Gitflow Standards
2.2.Committen und Prüfen von Code
2.3. Kodierungsstandards
2.4. Technische Dokumentation
3. Testen
3.1. Die drei Ebenen des Testens
3.2. Software-Tests in CI/CD
4. Deployment - Hurra!
4.1 Automatisches Deployment und Pipelines
Und natürlich ist ein Hauch von agilem Projektmanagement nötig, um 1 bis 4
zusammenzuhalten. Obwohl er nicht direkt an der Entwicklung beteiligt ist, ist der Projektmanager
dafür verantwortlich, die Arbeit durch den gesamten Prozess und bis zum Abschluss zu führen.
Für MVPs bedeutet dies, alle Schritte für eine erfolgreiche Markteinführung zu durchlaufen, mit
testbaren Meilensteinen und einem klaren Zeitplan, um die Time-to-Market zu verbessern. Sobald das
MVP zu wachsen beginnt, führen wir eine kontinuierliche Entwicklung durch, mit kleinen Iterationen
und regelmäßigen Deployments, um so viel Feedback wie möglich zu sammeln. Wenn Sie dachten, dass die
Softwareentwicklung nach dem Marktstart endet, liegen Sie falsch. Software-Entwicklung endet nie.
Niemals! :)
1/4 SETUP
Vor der Arbeit noch etwas mehr Arbeit.
Wie Sie vielleicht aus den vorangegangenen Artikeln bemerkt haben, gibt es
eine Menge Dinge, die eingerichtet werden müssen, bevor die eigentliche Entwicklung beginnen kann.
Tatsächlich sind es so viele, dass es sich so anfühlt, als wäre der größte Teil der Arbeit schon
erledigt, bevor die eigentliche Arbeit beginnt. Aber glauben Sie uns, der größte Teil liegt noch im
Code. Deshalb muss alles optimal eingerichtet werden.
Zu Beginn eines Projekts/MVP verbringen Entwickler oft eine gewisse Zeit mit dem Einrichten. Das
kann alles bedeuten, von "Oh, ich richte gerade die Build-Automatisierung ein" bis zu "Bitte nicht
stören. Ich kümmere mich um das Abhängigkeitsmanagement und habe noch keinen Kaffee getrunken".
Während es tausende von Tools gibt, um "die Grundlagen" einzurichten, sind die zeitaufwändigsten
Teile immer die projektspezifischen. Das liegt daran, dass die Entwickler die richtige Umgebung, das
richtige Werkzeug, die richtigen Bibliotheken und die grundlegende Codestruktur für die aktuell
benötigten Funktionalitäten einrichten müssen, basierend auf einem bestimmten Technologie-Stack und
gemäß der vereinbarten technischen Lösung. Wir beziehen die Einrichtung immer in unsere technischen
Kostenvoranschläge ein (mehr zu Kostenvoranschlägen hier),
gerade weil der Zeitaufwand dafür von Projekt zu Projekt variiert.

Abgesehen von den spezifischen Anforderungen gehen wir bei der Einrichtung des Ökosystems für ein Web-Entwicklungsprojekt in der Regel nach einer der folgenden Varianten vor:
- Wir erstellen das Projekt-Repository
- Wir initialisieren Git-Flow innerhalb des erstellten Repositorys (mehr zu Gitflow-Standards und der Repository-Struktur weiter unten)
- Wir installieren erforderliche Pakete und Abhängigkeiten (z. B. Laravel Passport für die Authentifizierung)
- Wir richten die Datenbank ein
- Wir richten Redis für die Zwischenspeicherung und die Abarbeitung von Warteschlangen ein
- Wir richten einen Staging-Server für die automatische Bereitstellung ein
- Wenn das Projekt einen Dateiupload erfordert, richten wir Buckets und ein Upload-System ein
2/4 ENTWICKLUNG
Sich im Gitflow befinden
Entwickler schreiben Code. Der Code wird sicher gespeichert und mit Hilfe
eines Versionskontrollwerkzeugs, normalerweise Git, freigegeben. Stellen Sie sich Git als ein
wirklich fortschrittliches Google Docs vor, ein Tool, mit dem Sie zusammenarbeiten, eine Historie
der Änderungen verfolgen, Änderungen überprüfen oder zu einer früheren Version zurückkehren können.
Im Gegensatz zu Google Docs erlaubt Git jedoch die Koexistenz mehrerer Versionen der "Wahrheit". Im
Wesentlichen hat jeder Entwickler eine Kopie des Repositorys, im Gegensatz zu Google Docs, wo jeder
an einer zentralisierten Kopie arbeitet. In Git können Sie z. B. mehrere Versionen der Software
gleichzeitig in Produktion haben oder Fehlerbehebungen für eine frühere Version liefern.
Da jeder Entwickler seine Version der "Wahrheit" hat, muss es einen Weg geben, Konflikte zu
vermeiden. Es müssen einige Regeln aufgestellt werden, um die Arbeit mit so vielen Versionen weniger
verwirrend zu machen. Diese Regeln werden Gitflow genannt. Gitflow ist nur eine von mehreren
Möglichkeiten, den Arbeitsablauf des Verzweigens und Zusammenführens zu verwalten, aber es ist
wahrscheinlich die beliebteste.

Einfach ausgedrückt, ist Gitflow ein Satz von Regeln, die jedes
Teammitglied befolgt, wenn es ein Stück Code einreicht. Gitflow legt fest, was an einen bestimmten
Zweig übermittelt werden soll und wie ein Zweig noch weiter verzweigt oder in einen anderen Zweig
zusammengeführt werden soll. Dies ist wirklich nützlich, um die Versionskontrollpraktiken zwischen
den Teams zu standardisieren und um das Onboarding von Projekten zu beschleunigen. Im Grunde
genommen weiß man, wo sich alles befindet, ohne dass man auf die Projektspezifika eingehen
muss.
Das grundlegende Gitflow-Modell besteht aus zwei Hauptzweigen (Master und Develop) und drei
Arbeitszweigen (Feature, Release, Hotfixes). In einigen Versionen von Gitflow gibt es auch
Support-Zweige, die z. B. dazu dienen, Fehlerbehebungen für ältere Versionen der App anzubieten. Im
Gegensatz zu den Hauptzweigen haben die Arbeitszweige immer eine begrenzte Lebenszeit.
- Master- dies ist Live-, Produktionscode. Wenn sie ein neues Feature erstellen, arbeiten die Entwickler nicht direkt an diesem Zweig. Sie erstellen neue Feature-Zweige und wenn sie fertig sind, werden die Änderungen über Develop zurück in Master zusammengeführt.
- Develop - auch bekannt als Staging, fungiert als Puffer zwischen dem, was in Bezug auf die Entwicklung als fertig angesehen wird, und dem, was tatsächlich in Produktion ist. Nach dem Gitflow-Modell wird alles zuerst in diesen Zweig und dann in Master zusammengeführt. Deshalb nennen ihn manche auch den "Integrationszweig". Von hier aus werden alle automatischen nächtlichen Builds erstellt.
- Feature - wird verwendet, um neue Funktionen für die kommende oder eine weit entfernte zukünftige Version zu entwickeln. Feature-Zweige existieren so lange, wie das Feature in der Entwicklung ist, werden aber irgendwann wieder in Develop zusammengeführt oder verworfen.
- Release - unterstützt die Vorbereitung einer neuen Produktionsversion. Dies ermöglicht kleinere Fehlerkorrekturen und die Vorbereitung von Metadaten für ein Release (Versionsnummer, Build-Daten, Versionshinweise usw.). Indem all diese Arbeiten in einem Release-Zweig durchgeführt werden, wird der Develop-Zweig freigegeben, um Funktionen für das nächste große Release zu empfangen.
- Hotfixes - werden verwendet, um Probleme in der Produktion schnell zu beheben. Wenn ein kritischer Fehler in einer Produktionsversion sofort behoben werden muss, kann ein Hotfix-Zweig von dieser Produktionsversion abgezweigt werden.
Wir verwenden spezifische Feature-Zweige für jede Aufgabe (mehr zu Aufgaben und Projektplanung hier). Alle Aufgaben werden in ihrem eigenen Feature-Zweig gelöst und wenn das erledigt ist, werden sie in Develop zusammengeführt. Auf diese Weise haben wir einen stabilen Develop-Zweig, der regelmäßige und kontinuierliche Releases unterstützt.
Die subtile Kunst des Commitings und der Überprüfung von Code
Damit Code tatsächlich in einem Versionskontrollsystem gespeichert werden kann,
muss er zunächst eingereicht und dann genehmigt werden. Man kann Code durch Pull-Requests
hinzufügen. Grundsätzlich bedeuten "Pull Requests", dass Sie den Betreuer des Repositorys bitten,
Ihren Code einzubringen. Pull-Requests enthalten einen oder mehrere Commits.
Eine Pull-Request ist immer mit einem Zweig verbunden. Mit anderen Worten, eine Pull-Request ist
eine Anfrage, einen Zweig in einen anderen zusammenzuführen und wird nach einem oder mehreren
Commits ausgegeben. Gute Commits folgen dem Single Responsibility Prinzip, was bedeutet, dass ein
Commit eine Sache im Code ändert und nur eine Sache. Sie können dieses Prinzip leicht in Ihrer
Commit-Nachricht testen. Wenn Sie das Wort "und" erreichen, hören Sie auf :)
Wir mögen es, Commit-Nachrichten auf Code-Ebene und auf den Punkt zu halten und
Pull-Request-Beschreibungen für ein übergeordnetes, architektonisches Verständnis der Änderung zu
verwenden. Eine High-Level-Zusammenfassung des Problems ist sehr nützlich für Leute, die durch die
Geschichte des Repositorys gehen, zusätzlich zu den einzelnen Code Änderungen. Das ist der Grund,
warum wir es vermeiden Commits beim Merge zu löschen, damit wir leicht in der Lage sind, die
historischen Änderungen zu verfolgen.
Nachdem ein Pull Request erstellt wurde, kommt ein Teammitglied, um die vorgeschlagenen Änderungen
zu überprüfen. Es gibt unzählige Artikel darüber, wie man gute Pull Requests einreicht, d.h. Pull
Requests, die Ihr Leben und das der Reviewer einfacher machen, aber was wir als besonders nützlich
empfunden haben, sind Pull Request Templates. Wir haben einen ganzen Artikel über das Thema
geschrieben und sogar einige der Pull Request Vorlagen, die wir für Frontend und Backend verwenden,
mit aufgenommen. Um es kurz zu machen, wir verwenden sie als Checklisten; die Person, die einen Pull
Request einreicht, kann die Checkliste durchgehen und sicherstellen, dass nichts wichtiges
ausgelassen wurde.

Der Reviewer kann dann die Pull-Review-Beschreibung lesen, auch die Checkliste durchgehen und sich einen Überblick über den Fortschritt verschaffen, der gemacht wurde. Einen Pull Request zu überprüfen ist genauso eine Kunst wie einen einzureichen. Feedback zu der Arbeit von jemand anderem zu geben, kann knifflig sein, aber wir versuchen immer diese drei einfachen Regeln zu befolgen, wenn wir Pull Requests überprüfen:
- Alles sorgfältig lesen. Dazu gehören Titel, Beschreibungen, Checklisten, Screenshots und Videos, falls vorhanden. Auch Verweise auf verwandte Themen/Tickets.
- Nicht nur auf das Problem hinweisen. Wenn möglich, eine alternative, einfachere Vorgehensweise vorschlagen.
- Höflich und hilfsbereit sein.
Programmieren mit Stil (und Standards)
Stellen Sie sich vor, Sie wachen eines Tages auf und können Ihre eigene
Handschrift nicht verstehen. Nun stellen Sie sich vor, Sie hätten am Vortag etwas wirklich Wichtiges
aufgeschrieben. So würde es sich anfühlen, wenn Sie auf Ihren eigenen Code zurückblicken, ohne
Codierungsstandards. Multiplizieren Sie dies dutzendfach und Sie erhalten ein ganzes Team von
Entwicklern, die gemeinsam an der gleichen unverständlichen Codebasis arbeiten.
Coding-Standards sind langweilig. Tatsächlich sind sie so langweilig, dass die meisten von ihnen
automatisch von statischen Code-Analysatoren, auch bekannt als Linters, erzwungen werden. Aber sie
existieren aus mehreren Gründen. Einer davon ist die Vernunft, Ihre und die von allen anderen. Der
andere ist die Verringerung der Wartungskosten und der technischen Belastung. Die Wartung eines
Codes macht im Durchschnitt 60% seiner Lebenszeitkosten aus, was bedeutet, dass der Code von einem
Entwickler zahlreiche Male gelesen wird, nachdem er zum ersten Mal geschrieben wurde. Je einfacher
der Code also zu lesen ist, desto billiger ist er am Ende.
Wir setzen Codierungsstandards durch Linters und Code-Peer-Reviews durch. Wie bereits erwähnt, sind
Linters Werkzeuge, die Code gegen einen Satz von Regeln prüfen und Verstöße gegen diese Regeln als
Fehler markieren. Ein Linter kann auch so konfiguriert werden, dass er die Einhaltung eines
bestimmten Style-Guides überprüft, abhängig von der Sprache, in der der Code geschrieben wurde (z.B.
PSR-2 für PHP). Linters sind im Laufe der Zeit viel besser darin geworden, Inkonsistenzen oder sogar
unnötige Komplexität im Code zu erkennen, aber sie haben immer noch ihre Grenzen. Wir verwenden
Code-Peer-Reviews, um Probleme auszusortieren, die sonst von Linters unbemerkt bleiben würden, wie
z. B. fehlerhafte logische Strukturen.

Was passiert, wenn man nicht in Kodierungsstandards investiert? Es entsteht die
Hölle für Softwareentwickler. Sie haben PHP zusammen mit HTML, CSS und Javascript in einer Datei.
Kommentare variieren in ihrer Vagheit von "oopsie" bis "kleinere Änderung" oder "arbeite an Feature
x", gefolgt von 20 Commits hintereinander, ohne dass man sie auseinanderhalten kann. Die Namen von
Variablen, Klassen und Methoden sind inkonsistent und voller Tippfehler und ganze Codeabschnitte
sind auf seltsame Weise eingerückt.
Obwohl sie für Code-Interpreter syntaktisch nicht von Bedeutung sind, sind Kodierungsstandards für
Menschen von Bedeutung. Sie erleichtern das Lesen von Code, indem sie Regeln bezüglich der folgenden
Punkte durchsetzen:
- Formatierung: das sorgt dafür, dass einem nicht die Augen bluten. Dinge wie die Einrückung von Blockanweisungen, die Platzierung von geschweiften Klammern, Leerzeichen
- Namenskonventionen: Soll die Variable wirklich eine_lange_und_vage_Variable heißen?
- Kommentare : Zugegeben, es kann schwierig sein, effektive Regeln für die Kommentierung zu finden. Solche, die in einem Peer-Review relevant sind, aber nicht zu einer hirnlosen Checklisten-Aktivität werden, die Notizen wie: "Du hast vergessen, die Zeile 31 zu kommentieren". Eine gute Faustregel ist, dass Kommentare dort auftreten, wo der Code nicht für sich selbst spricht. Gute Kommentare erklären auch, warum der Code tut, was er tut, und nicht wie.

Der faule Entwickler überspringt die technischen Dokus. Und bereut es später.
Erinnern Sie sich, wie wir erwähnt haben, dass es eine gute Idee ist, den Code richtig zu
kommentieren? Raten Sie mal! Man kann auch Code-Dokumentation auf der Basis von Kommentaren
erzeugen. Wir empfehlen zwar nicht, dies zur einzigen Dokumentationsquelle zu machen, aber es gibt
einen bequemen Weg, um anzufangen. Technische Dokumentation ist in diesem Sinne ähnlich wie Pizza.
Selbst wenn sie schlecht oder zu wenig ist, ist sie immer noch besser als nichts.
Viele Sprachen haben die Möglichkeit, Kommentare in schön gerenderte Dokumente zu verwandeln, die
auf andere Teile der Dokumentation verweisen können. So etwas wie eine Wikipedia-Seite für den Code.
Wir verwenden Dokumentationskommentare (bekannt als Doc Blocks) insbesondere für die
API-Dokumentation. Je weiter entfernt vom Quellcode Ihre API-Dokumentation ist, desto
wahrscheinlicher ist es, dass sie mit der Zeit veraltet oder ungenau wird. Die beste Strategie ist
also, die Dokumentation direkt in den Code einzubetten und sie dann mit einem Tool zu extrahieren.

Wenn sich User Stories auf die Erfahrung des Endbenutzers mit der App konzentrieren, konzentrieren
sich die technischen Dokumente auf die Spezifikationen, die dies ermöglichen. Meistens werden
mehrere Funktionalitäten benötigt, um die in der User Story beschriebene Aktion zu liefern. Und in
fast allen Fällen fließen mehrere Entwicklungsentscheidungen in eine Funktionalität ein. Nehmen Sie
zum Beispiel die einfache Aktion des Einloggens. Welche Art der Anmeldung soll implementiert werden,
E-Mail und Passwort oder Social Login? Sollen die Eingabefelder Einschränkungen haben? Wie sollen
sie Fehler erkennen und behandeln, wie z.B. ungültige E-Mail-Adressen? Wie lange sollen die
Informationen für die "Remember Me"-Option gespeichert werden? Unterm Strich lassen sich technische
Dokumentationen nicht vom Entwicklungskontext trennen. Deshalb schreiben wir technische
Dokumentationen, während wir programmieren, und wir halten sie während des gesamten
Entwicklungsprozesses auf dem neuesten Stand.
Für Community-Projekte, wie APIs, Bibliotheken oder einige der Open-Source-Arbeiten, die wir gemacht
haben, ist die erste Interaktion, die jemand mit dem Projekt hat, normalerweise durch die
README-Datei. In solchen Fällen ist eine gut strukturierte, gut geschriebene README-Datei der erste
Schritt, um Ihr Produkt einem größeren Publikum vorzustellen. In der Tat nehmen einige diesen
"ersten Schritt" wörtlich und plädieren für eine README-getriebene Entwicklung. Im Folgenden finden
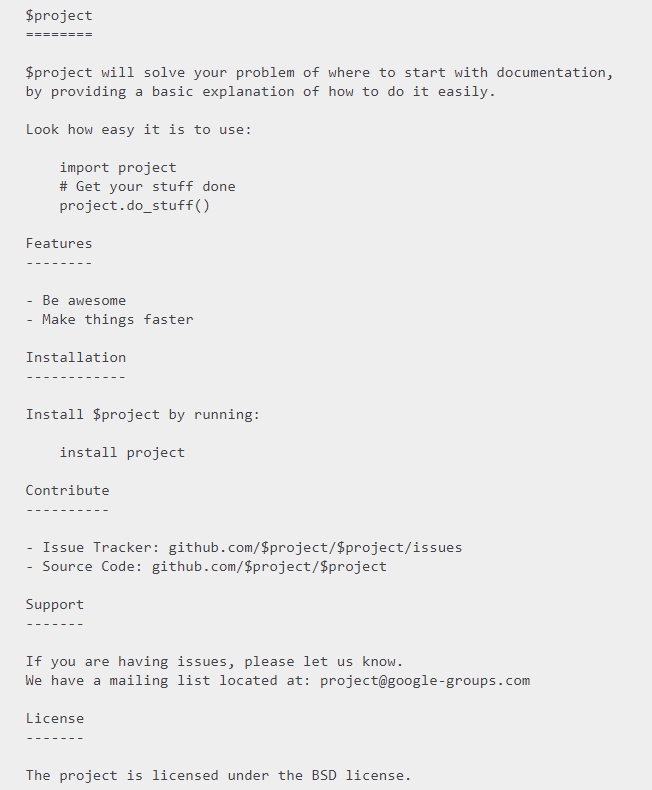
Sie eine einfache Vorlage für das Schreiben von leicht lesbaren und nützlichen README-Dokumenten.
3/4 TESTEN
Die drei Ebenen des Testens
Wie das Sprichwort sagt, ist der Zweck des Testens nicht, Dinge zu
zerstören, sondern die Illusion zu zerstreuen, dass Dinge funktionieren. Das kann von der
Sicherstellung, dass Ihre App nicht abstürzt, sobald jemand seinen Namen in ein Eingabefeld
schreibt, bis hin zu den obskursten Randfällen reichen.
Die Welt der Software-Qualitätssicherung ist riesig. Es gibt jedoch drei grundlegende Ebenen, auf
denen eine App von Entwicklern getestet wird, bevor sie ihre Arbeit jemand anderem zeigen, d. h.
bevor die App von Endbenutzern oder dem Kunden getestet wird, auch bekannt als User Acceptance
Testing (UAT).
Die folgenden Tests werden von Entwicklern geschrieben, um immer komplexere Teile des Codes zu
überprüfen. Sie sind in der Regel in der gleichen Sprache wie die App geschrieben und werden
zusammen mit dem Hauptcode der Software in einem Versionskontrollsystem gespeichert. Normalerweise
schreiben wir die Tests während des Programmierens und sie werden in der gleichen Weise wie unser
gesamter Code überprüft.
1. Unit Tests - sie sind die Bausteine des Software-Testens. Entwickler schreiben Unit-Tests,
um sicherzustellen, dass eine bestimmte Codeeinheit (z. B. Methode, Klasse, Funktion) über einen
Bereich von gültigen und ungültigen Eingaben hinweg wie erwartet funktioniert. Angenommen, Sie haben
eine Funktion 2VAL, die bei zwei Werten, x und y, immer x+y zurückgibt. Der Unit-Test würde die
Funktion mit zwei Eingabewerten ausführen und bestätigen, dass die Ausgabe x+y ist.
2. Feature Tests - sie decken die wichtigsten Funktionalitäten einer Komponente oder eines
Systems ab. Wie die Funktionen funktionieren sollen, kann in der Spezifikation der App oder in der
Produktdokumentation beschrieben werden und kann von sehr technisch (Geben Endpunkte das zurück, was
sie zurückgeben sollen?) bis hin zu selbsterklärend (Funktioniert Social Login?)
3. Integrationstests - Auf einer höheren Ebene als Funktionstests. Sie verifizieren, dass
verschiedene Komponenten Ihrer App, wie Module oder Dienste, gut zusammenarbeiten. Das kann zum
Beispiel das Testen der Interaktion mit der Datenbank sein oder das Sicherstellen, dass
Microservices gut zusammenspielen.
Nachdem sie vom Entwicklungsteam getestet wurden, durchlaufen Apps in der Regel eine Form von User
Experience Testing. Dies kommt so nah wie möglich an das heran, was passiert, wenn die App im Alltag
von normalen Benutzern verwendet wird, von etwas so Einfachem wie dem Absenden eines Formulars bis
hin zu komplexeren Szenarien. Der Zugriff auf die App erfolgt in einer Staging-Umgebung und wird in
der Regel mit Dummy-Daten bestückt. UAT ist Teil dieser Art von End-to-End-Tests und ist in der
Regel eine großartige Gelegenheit für Kunden, dem Entwicklungsteam Feedback zu geben und Funktionen
anhand von Geschäftsanforderungen zu validieren.
Software-Tests in CI/CD
Das Testen von Software ist zeitaufwendig. Software von Hand zu testen ist noch schlimmer. Wenn es
doch nur eine Möglichkeit gäbe, Tests nicht nur zu automatisieren, sondern sie auch in Ihren
Entwicklungs-Workflow zu integrieren. Hier kommt CI/CD ins Spiel, kurz für Continuous
Integration/Continuous Delivery oder Deployment. Richtig, CD kann entweder für Delivery oder für
Deployment stehen (verwirrend, wissen wir), abhängig vom Grad der Automatisierung. Aber wir wollen
nicht zu weit vorpreschen. Auf diese Unterschiede werden wir im nächsten Abschnitt noch genauer
eingehen.
Für den Moment ist es wichtig zu wissen, dass CI/CD eine Reihe von Praktiken ist, die es
Entwicklungsteams ermöglichen sollen, Änderungen schneller und mit weniger Konflikten zu liefern,
sowohl auf menschlicher als auch auf Code-Ebene. Die primäre Idee ist es, Build, Test und Deployment
durch Skripte zu automatisieren, um: a.) Bugs, Merge-Konflikte, menschliches Versagen und alles, was
zwischen Ihnen und einem erfolgreichen Release steht, zu minimieren. b.) Code kontinuierlich zu
bauen, zu testen und zu deployen und einfach zurückzusetzen, wenn etwas schief läuft. Das bedeutet,
dass Releases weniger schwierig zu verwalten und weniger riskant sind und daher häufiger stattfinden
können.
Nehmen wir an, der Code ist in einem Git-Repository gespeichert. Die meisten Versionskontrollsysteme
haben heutzutage CI/CD-Tools integriert, wie GitLab CI/CD oder GitHub Actions. Diese Werkzeuge
sorgen dafür, dass Tests automatisch ausgeführt werden, sobald ein neues Stück Code übertragen wird.
Anders ausgedrückt: Man kann ein Stück Code nur dann committen, wenn jeder einzelne Test in der
Codebasis erfolgreich ist und es Tests gibt, die den gesamten neuen Code in der Codebasis abdecken.
Der Punkt hier ist ein doppelter. Erstens, um sicherzustellen, dass der neue Code der gerade
geschrieben wurde, nicht den alten Code kaputt macht. Stellen Sie sich das wie Ihr vergangenes Ich
vor, das Ihr zukünftiges Ich davor bewahrt, etwas Schreckliches zu tun. Zweitens, um automatisch
festzustellen, ob der neue Code Tests hat.
Genau wie beim Bestehen einer Prüfung muss der Code bestimmte Anforderungen erfüllen, um einen Test
zu bestehen. Bei automatisierten Tests werden diese Anforderungen in Skripten als Sequenzen von
Aktionen niedergeschrieben und was erwartet wird, wenn diese Aktionen ausgeführt werden. Um zu
überprüfen, wie viel des Codes tatsächlich durch Skripte abgedeckt ist, wird eine universelle Metrik
verwendet: die Testabdeckung. Diese Metrik berechnet, wie viel von dem Code läuft, wenn die Tests
ausgeführt werden. Die Teile, die nicht laufen (und solche Teile wird es immer geben), werden von
den vorhandenen Tests nicht abgedeckt.
Wenn CI/CD dafür verantwortlich ist, was automatisch gemacht werden kann, diktiert der Workflow zum
Verzweigen und Zusammenführen (erinnern Sie sich an Gitflow?) letztendlich, wie die Dinge
eingerichtet werden sollten. Ein grundlegendes CI/CD-Setup, das einer Gitflow-Logik folgt, könnte
etwa so aussehen:
- Automatisierte Tests auf allen Zweigen außer Master ausführen.
- Automatisches Deployment nach jeder Zusammenführung in den Master.
CI/CD und Gitflow sind wichtige Bestandteile unseres Entwicklungsprozesses. Wir verwenden sie, um sicherzustellen, dass Tests vorhanden sind, Releases problemlos durchgeführt werden können und jeder dem gleichen Workflow folgt. Da es den Druck vom Tag der Veröffentlichung nimmt (keine Notwendigkeit, die Entwicklung für die Veröffentlichung zu unterbrechen, Probleme sind einfacher zu beheben, da sie in kleinen Chargen implementiert werden), ermöglicht es uns, häufiger zu veröffentlichen und viel schneller Feedback von unseren Kunden zu erhalten.
4/4 DEPLOYMENT
In den Kaninchenbau. Automatische Bereitstellung und Pipelines
Mit CI/CD können Sie alles vom Bauen und Testen bis hin zum Deployment und
Release automatisieren. "Pipeline" ist ein anschaulicher Begriff, der meist mit CI/CD in Verbindung
gebracht wird. Er wird verwendet, um sowohl den Grad der Automatisierung eines Workflows als auch
die Abfolge der Schritte zu definieren, die ausgeführt werden müssen.
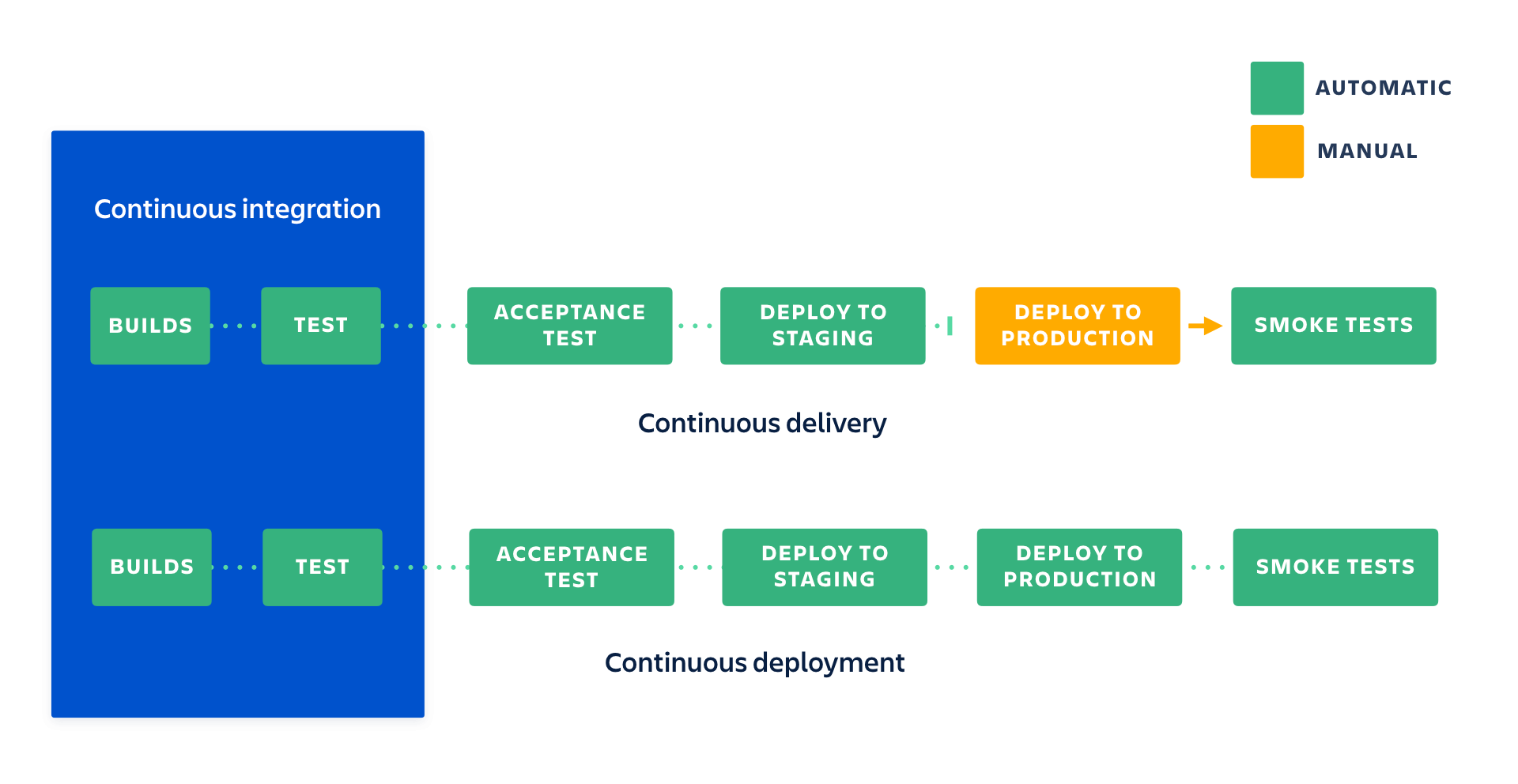
- Eine Pipeline für kontinuierliche Integration konzentriert sich auf das automatische Erstellen und Testen von Änderungen an der Codebasis und stellt sicher, dass der Code den gestellten Anforderungen entspricht. Sie legt großen Wert auf automatisierte Tests und darauf, sicherzustellen, dass fehlerhafter Code nicht in den Hauptzweig integriert wird. Diese Methode stellt sicher, dass der Code automatisch geprüft wird, erfordert aber, dass das Deployment dieser Änderungen von manuell ausgelöst wird.
- Eine Continuous-Delivery-Pipeline bedeutet, dass nicht nur automatisierte Tests für jede neue Funktion, Verbesserung oder Fehlerbehebung vorhanden sind, sondern auch der Release-Prozess teilweise automatisiert ist. Der Auslöser für das Deployment in die Produktion ist immer noch manuell, aber sobald das Deployment durch die Auswahl eines Builds und das Drücken des Release-Buttons gestartet wurde, sollte kein menschliches Eingreifen mehr nötig sein.
- Eine Continuous-Deployment-Pipeline ist ein Schritt über Continuous Delivery hinaus. Die App wird so eingestellt, dass sie automatisch bereitgestellt wird, und es sind keine menschlichen Eingriffe während der gesamten Pipeline erforderlich, mit Ausnahme der eigentlichen Codeüberprüfung. Sobald eine Änderung alle Phasen in der Pipeline durchläuft, wird sie direkt für die Kunden freigegeben. Nur ein fehlgeschlagener Test verhindert, dass eine neue Änderung für die Produktion bereitgestellt wird.
Wir betreiben eine CI/CD-Pipeline, um die wichtigsten Schritte im Bereitstellungsprozess zu automatisieren:
- Vorbereitung der Zielumgebung, entweder durch Installation oder Konfiguration der notwendigen Software oder durch Inbetriebnahme eines virtuellen Hosts
- Deployment
- Deploymentbezogene Aufgaben, wie z. B. das Ausführen von Datenbankmigrationsskripten
- Durchführen einer erforderlichen Konfiguration
- Durchführen eines Deployment-Tests (auch "Smoke-Test" genannt), um sicherzustellen, dass wichtige externe Dienste erreichbar sind und das System funktioniert. So können z. B. die Verfügbarkeit von Netzwerkadressen/Servern oder das Vorhandensein von Zertifikaten und Registrierungsschlüsseln oder die Einhaltung der Mindestanforderungen an den Festplattenspeicher überprüft werden.
Wir automatisieren die Bereitstellung für Projekte, die häufige Releases und enge Feedback-Schleifen erfordern. Außerdem können wir so sicherstellen, dass alles in der Praxis wie erwartet funktioniert. Das Deployment in eine Produktionsumgebung erst dann durchzuführen, wenn die Entwicklung abgeschlossen ist, bedeutet, dass Sie keinerlei Garantien haben, dass eine bestimmte Version für die Endbenutzer funktioniert. Mit automatisierten Deployments können Sie Ihren Code in einer produktionsähnlichen Umgebung so viele Male wie nötig testen.
Bereit anzufangen?
Wenn Sie ein Start-up sind, das einen technischen Partner für die Fahrt sucht, suchen Sie nicht weiter. Wir sind darauf spezialisiert, Start-ups bei der Validierung, Einführung und Skalierung ihres MVP zu unterstützen. Kontaktieren Sie uns jetzt, um Ihr Projekt auf den Weg zu bringen.
 Facebook
Facebook LinkedIn
LinkedIn Twitter
Twitter